
書類を無料でOCRスキャンし、そのテキストデータをパソコン側で活用する方法を解説していきます。
(ただし文字認識率に関してはなんとも言えないので、処理後のデータ確認は必須です)
まずはiPhoneのアプリを使用して、書類のテキスト抽出をする方法なのですが、
使うアプリケーションは色々試したのですが、Microsoftが提供している、
Microsoft Lens:PDF Scanner を使っていきます。

(こちらを使用するにはmicrosoftアカウントが必要になりますので、持っていない方は新規で作成していきましょう。)
まずアプリを起動したら、以下の赤丸の“処理“をタップします。
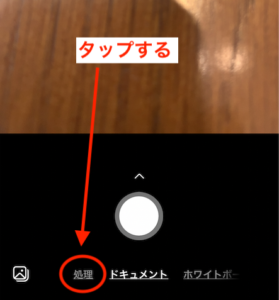
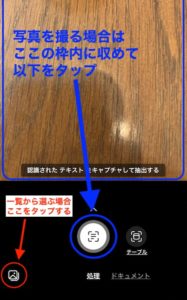
予め書類の写真を撮っている場合は、赤丸をタップして写真へのアクセスを許可 し、一覧から選択しましょう。
写真を撮る場合は、書類が枠内に収まる様にして“青丸”をタップし、写真を撮りましょう。
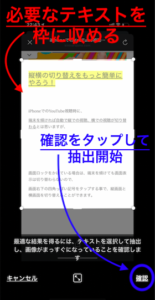
次に抽出したい領域を任意で選択して、青丸の”確認”をタップします。
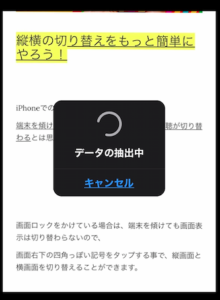
するとデータの抽出をしてくれます。
終了すると以下の画面になります。(完璧には文字認識できていませんが‥)
 そして”青丸“の“共有する”をタップしましょう。
そして”青丸“の“共有する”をタップしましょう。
パソコンでデータを確認編集したい場合は、
メールのアイコンを選択してパソコンで受信出来るメールアドレス宛に送信しましょう。

パソコン側で受信したメールを開くと、本文に抽出したテキストがありますので、
あとはそのテキストデータを任意のアプリケーションに貼り付けて使用していきましょう。
あくまでテキストの抽出なので、書類のレイアウトなどは維持されませんが、
長文などの文章の再編集や、文字の削除や追加などの時に使ってみてはいかがですか?